AI in the Philippines: Building the Ecosystem from the Ground Up
A reflection on what it has taken to build the artificial intelligence and data science ecosystem in the Philippines — from research and education to governance and national …
Erika Fille T. Legara is a pioneering Filipina scientist and one of the leading women in AI in the Philippines, working across government, academia, and industry as a data science and AI practitioner. She is the inaugural Managing Director and Chief AI and Data Officer of the Philippine Center for AI Research, and an Associate Professor and Aboitiz Chair in Data Science at the Asian Institute of Management, where she founded and led the country’s first MSc in Data Science program from 2017 to 2024. An Eisenhower Fellow, her work focuses on responsible AI governance and algorithmic auditing. She serves on corporate boards, is a Fellow of the Institute of Corporate Directors, an IAPP Certified AI Governance Professional, and a co-founder of a technology company. Her recognitions include the 2020 NAST Outstanding Young Scientist Award, TOYM and TOWNS honors, and selection as an Asia 21 Young Leader (Class of 2022).
PhD Physics
University of the Philippines Diliman
MS Physics
University of the Philippines Diliman
BSc Physics (cum laude)
University of the Philippines Diliman
A reflection on what it has taken to build the artificial intelligence and data science ecosystem in the Philippines — from research and education to governance and national …

AI fails when the data underneath it fails. Fragmented systems, no common identifiers, no clear ownership, and no accountability when things break are enough to undermine even the …
I’ve started a newsletter called Signal & Noise where I write about data, innovation, human systems, and complex systems. Sometimes technical, sometimes observational, always …

Wrapping up our first week has been surreal. I still remember the planning sessions with our lovely program officer, Seya Fadullon, and all the preparations that went into this. …

It was Day 4. Our “CERN Day” :) Even though it was my second time, I was still quite giddy. It’s CERN!! The second time hit differently, though. I went with our GESDA Science …
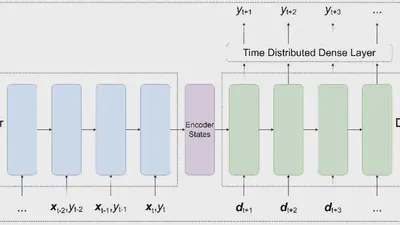

Digital Transformation and Decision Intelligence in Diplomacy Foreign ministries today operate in an environment defined by information overload, compressed timelines, and growing …

As I always say (or warn!), AI transformation isn’t for the faint of heart. Boards must lead with a sharp DSAI Strategy (Data Science and AI) that aligns with organizational goals. …

Had a fantastic time in Seoul to join a small-group, insightful discussion on Operationalizing AI Governance, with a special focus on standards setting. It was so nice and …

Honored to have been the keynote speaker at the 8th Ayala Corporation-FINEX 𝑭𝒊𝒏𝒂𝒏𝒄𝒆 𝑺𝒖𝒎𝒎𝒊𝒕 and FINEX 9th GMM. Thank you for the invitation to share about the Center for AI Research …

At the 2024 AACSB ICAM, joining a distinguished plenary panel alongside Asian Institute of Management President and Dean Jikyeong Kang, Dean Saïd Business School, University of …